
- Published on
Scraping Google Images in Rust
At some point in a programmer’s journey, one is bound to encounter web scraping: fetching information from a website in a non-standard fashion. Usually, we have to resort to web scraping if an API is non-existent or severely lacking in functionality, or simply too expensive.
Some websites are harder to scrape than others, which can be due to a variety of causes such as:
- Dynamic content lazy-loaded with JS
- Obfuscated HTML structures
- IP blocking or rate limiting
- CAPTCHAs
In this article, I’d like to explain how to scrape full-resolution images from Google in Rust, as the approach is rather different from what you’d expect. Although I could just wrap the Rust code up in a crate and publish it, I’d rather take the time to explain the general procedures to replicate within any language.
Avoiding Selenium
Initially, when I had to write image-grabbing code for ace-rs, I simply thought it was a matter of sending a GET request, selecting all <img> tags, and saving the src="[url]" attributes.
However, after some experimentation, I found that the img tags only contain a base64 encoded jpeg string of the heavily compressed and resized thumbnail, instead of a link to the full-resolution source image directly. In the interactive site, once you click on the thumbnail, it opens the full image using Javascript.
After encountering this issue, I was considering just hacking together Selenium code in a headless instance, but I decided to keep this as a last resort due to its several disadvantages as opposed to direct HTTP scraping:
- It suffers in performance due to having to render and process the entire web page
- Requires huge dependencies such as browser drivers and adds unwanted platform-specific setup complexity
Finding the data source
So I decided to keep digging around the client-rendered HTML, network requests, and scripts. My best bet was to carefully check for any possible directly stored “data sources” that the JS relied on.
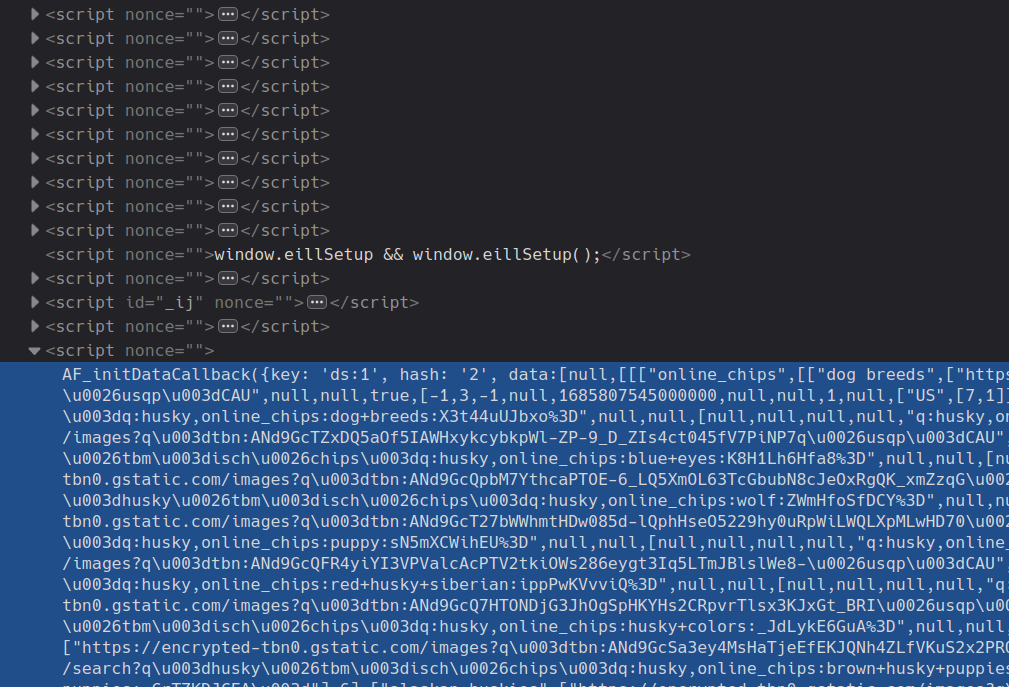
Aha! After carefully navigating through countless script tags containing miscellaneous JavaScript calls, I finally uncovered the gold. This AF_initDataCallback function seemed to have just what I was looking for, albeit in a severely incomprehensible and nested format with no clear keys in the JSON.
By putting it into a JSON prettifier and probing for any consistent patterns, I noticed the target URL was always embedded in an array matching the following constraints:
- First value (target URL) → type String
- Second and third values (irrelevant) → type Number
One last filter I needed to apply was excluding all links that began with https://encrypted-tbn0.gstatic.com — the cached thumbnails.
Implementing with Rust
With the theory out of the way, let’s dig right into the code! For this article, we’ll need the following dependencies first:
[dependencies]
anyhow = "1.0.71"
tokio = { version = "1", features = ["full"] }
regex = "1.8.4"
reqwest = "0.11.18"
serde = "1.0.163"
serde_json = "1.0.96"
json5 = "0.4.1"
json5is needed due to the JSON string containing unquoted keys.reqwestis an easy-to-use HTTP clientserdefor all parsing and de-serialization purposesanyhowallows us to use?(error propagation) with multiple types ofErrorvalues
Let’s begin by defining an asynchronous function called fetch_images that should output a Vec of URLs wrapped in anyhow::Result. Embed the query inside of the Google Images link, and we’ll build a request with a custom user-agent (avoids flagging their systems). Then, execute the GET request to fetch the main HTML.
async fn fetch_images(query: &str) -> Result<Vec<String>> {
let url = format!("https://google.com/search?q={query}&tbm=isch");
let client = reqwest::Client::builder()
.user_agent("Mozilla/5.0 (Linux; Android 9; SM-G960F Build/PPR1.180610.011; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/74.0.3729.157 Mobile Safari/537.36")
.build()?;
let content = client.get(&url).send().await?.text().await?;
// ...
}
Now we have to Regex to pinpoint the location of the JSON data inside the AF_initDataCallback function mentioned earlier and unwrap the value of data using json5. Index 56 seems to be the general area where the target URLs live.
let regex = Regex::new(r"AF_initDataCallback\((\{key: 'ds:1'.*?)\);</script>").unwrap();
let found = regex.captures(&content);
if let Some(found) = found {
let cap = found.get(1);
if let Some(cap) = cap {
let json: Value = json5::from_str(cap.as_str()).unwrap();
let decoded = &json.get("data").unwrap()[56]; // unorganized raw data
// TODO: filter ...
}
}
Ok(vec![])
Sweet, now a huge blob of messy JSON data with mostly unwanted information is at our fingertips. All we have to do now is apply the previously mentioned filters to extract what we’re looking for.
Let’s first define a helper function filter_nested_value that takes this blob and converts it into something we can work with. How? It recursively collects only the arrays with three elements, with which we can further filter down with our conditions.
// utility function
fn filter_nested_value(value: &Value) -> Vec<&[Value]> {
match value {
Value::Array(arr) if arr.len() == 3 => vec![arr.as_slice()],
Value::Array(arr) => arr.iter().flat_map(filter_nested_value).collect(),
Value::Object(obj) => obj.values().flat_map(filter_nested_value).collect(),
_ => vec![],
}
}
Back to handling the original decoded variable. This part is quite straightforward with a clever match statement using a match guard.
let urls: Vec<String> = filter_nested_value(decoded)
.into_iter()
.filter_map(|arr| match arr {
[Value::String(string_val), Value::Number(_), Value::Number(_)]
if !string_val.starts_with("https://encrypted-") =>
{
Some(string_val.to_string())
}
_ => None,
})
.collect();
return Ok(urls);
Conclusion
Although maybe not the most complicated “reverse-engineering” feat, the outlined approach to scraping for images from Google is undoubtedly involved and un-intuitive.
Another risk of web scraping that we must acknowledge is the lack of stability. This code is not guaranteed to work years down the line, in case they change up their website. However, this is our best (free) option, as their official Image Search API was deprecated in 2011.
Hope this article helped! Here’s some further reading if interested: