
- Published on
Union Find: A beautiful data structure for dynamic connectivity
Alternatively called a disjoint-set, the union-find data structure is a fast and elegant way of merging “forests” and keeping track of separate groups of elements. It can solve real problems such as dividing an into regions of similar color, or perhaps a more general problem—finding connected components in a graph.
Intuition
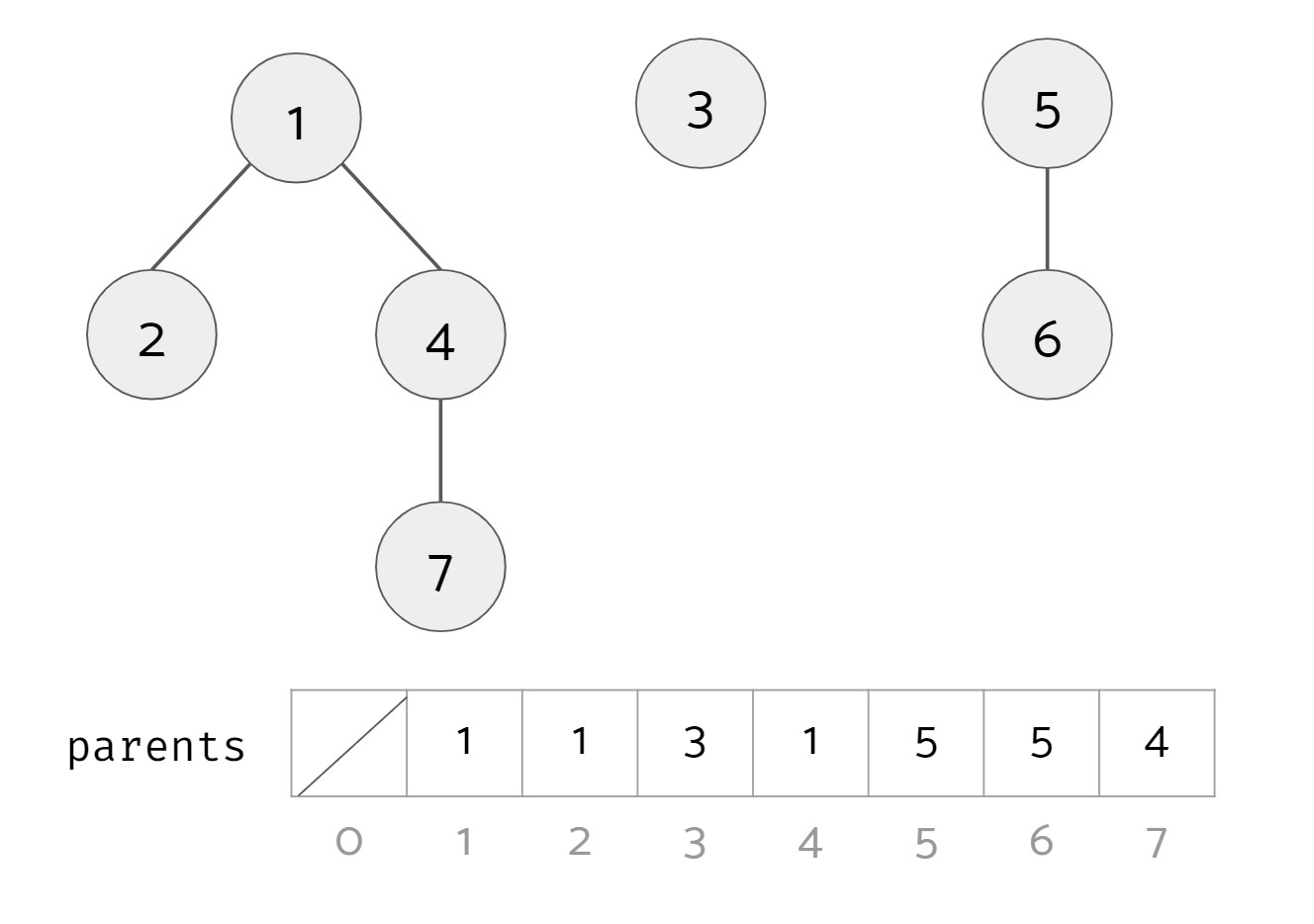
The basic idea is to maintain an array of indices, pointing to other elements within that array. Each element in the array points to the immediate ancestor, which recursively also points to its parent, until the root element is reached (i.e. it points to itself). The two main operations—you guessed it—are union and find. Rest assured, both of their implementations are relatively straightforward, so let’s take a look at them.
Find
The find operation returns the ultimate root of the set that element x belongs to. Each group or set in the data structure has its own unique root.
def find(i):
if parent[i] != i:
return find(parent[i])
return parent[i]
Union
We can merge separate group1 and group2 by setting the root of either group to point to the root of the other group.
def union(x, y):
root_x = find(x)
root_y = find(y)
if root_x != root_y:
parent[root_y] = root_x
Path Compression
This is a subtle, but huge optimization we can make in the find operation, in order to keep the trees relatively balanced and avoid linear structure (resembling a linked-list). The idea is to flatten out the path for an element x to its root when we initially call find(x) in order to speed up subsequent calls, because the path needed to traverse is shorter.
Ranking
This optimization involves attaching the smaller depth tree under the root of the deeper tree during union(x, y). We maintain a separate array with ranking statistics for each element. Rank is incremented for a root if and only if it was merged with another root with equal rank.
Think about why this is the case for a moment. If a shorter tree was merged with a larger tree, the larger tree’s height would still remain the same, regardless. With equal heights, the new root needs to be weighted higher, therefore we update the rank.
Final Implementation
Combining the union & find code, along with the optimizations we looked at, we arrive at following final implementation. I also included a self.count variable that conveniently keeps track of the number of disjoint sets within the structure.
class UnionFind:
def __init__(self, n):
self.count = n
self.parent = list(range(n))
self.rank = [0] * n
def find(self, i):
if self.parent[i] != i:
self.parent[i] = self.find(self.parent[i])
return self.parent[i]
def union(self, x, y):
root_x = self.find(x)
root_y = self.find(y)
if root_x != root_y:
if self.rank[root_x] < self.rank[root_y]:
root_x, root_y = root_y, root_x
self.parent[root_y] = root_x
self.rank[root_x] += self.rank[root_x] == self.rank[root_y]
self.count -= 1
Satisfiability of Equality Equations
Let’s take a look at an example Leetcode problem that can be solved with union-find. Remember, understanding the idea behind the problem, not the solution itself, will prove to be beneficial in the long-run when solving related problems.
Problem statement
You are given an array of strings
equationsthat represent relationships between variables where each stringequations[i]is of length4and takes one of two different forms:"a==b"or"a!=b". Here,aandbare lowercase letters (not necessarily different) that represent one-letter variable names.Return
trueif it is possible to assign integers to variable names so as to satisfy all the given equations, orfalseotherwise.
Example
Input: equations = ["a==b","b!=a"]
Output: false
Explanation: If we assign say, a = 1 and b = 1, then the first equation is satisfied, but not the second.
There is no way to assign the variables to satisfy both equations.
Idea
To begin, we initialize the disjoint-set with a total of 26 sets, each number signifying a single character. The following functions are simply generic implementations of the union-find operations, with path compression and ranking that we discussed earlier. It’s already coming in handy!
The heart of the solution lies within the way we build the disjoint-set. We iterate over each equation, and link the two variables in the disjoint set if they are equal. Notice how we use the union operation here, because of the transitive nature of these expressions. If a == b and b == c, than a must also equal to c. The union operation handles this perfectly because of how it links all variables that have some form of relationship with one another into a single group.
What if the variables, however, aren’t equal to each other? Well, since we are still in the midst of building the disjoint-set, we must delay the verification of whether or not this is possible to after we have the groups ready. For example, let’s assume b's root points to a, meaning they are both equal. However, if somewhere in the equations we had a != b before a == b, then we must wait until we finished “understanding” which groups have same values before we can even verify they aren’t the same.
So, we delay this by pushing a and b to an array of “tasks” to process after. We then simply iterate over these final tasks, and compare the root values for these in the disjoint-set to finally determine whether or not they are part of the same set. If these roots are not different, then it’s automatically impossible to declare that two values are unequal after knowing it’s equal! We can return false here without worrying about the rest.
Final code
def equationsPossible(equations: List[str]) -> bool:
parents = list(range(26)) # [a..z]
rank = [0] * 26
def find(cell):
if cell != parents[cell]:
parents[cell] = find(parents[cell])
return parents[cell]
def union(cell1, cell2):
root1, root2 = find(cell1), find(cell2)
if root1 != root2:
if rank[root1] < rank[root2]:
root1, root2 = root2, root1
parents[root2] = root1
rank[root1] += rank[root1] == rank[root2]
to_process = []
for equation in equations:
var1 = ord(equation[0]) - ord("a")
var2 = ord(equation[3]) - ord("a")
is_equal = equation[1] != "!"
if is_equal:
union(var1, var2)
else:
to_process.append((var1, var2))
for a, b in to_process:
if find(a) == find(b):
return False
return True
Time complexity: O(nlogn) — in the worst case, we end up merging n times.
Space complexity: O(n) — in the worst case, to_process contains all the n equations
More Problems
Practice makes perfect, so try these problems out on your own to truly grok this approach.
- https://leetcode.com/problems/min-cost-to-connect-all-points/
- https://leetcode.com/problems/number-of-enclaves/
- https://leetcode.com/problems/satisfiability-of-equality-equations/
- https://leetcode.com/problems/number-of-islands/
Conclusion
The union-find data structure is a favorite of mine and is a valuable addition to an algorist’s toolkit. Do note that sometimes DFS may simply be more suitable if the list of relationships are already given (perhaps in the form of an adjacency list). With more dynamic graphs, where relationships are changing, union find can be extremely powerful for solving the problem efficiently!